TL;DR: Hyperbolic discounting is an imperfect approximation for exponential discounting. It’s commonly pointed out that this causes humans to overvalue nearterm rewards, but it’s less commonly appreciated that this causes us to overvalue distant rewards as well. There’s a lot of evidence that humans use hyperbolic discounting, and it helps explain why humans pursue unrealistic longterm goals.
What is Hyperbolic Discounting?
⭐ If you search the words “hyperbolic discounting”, Google tells you that it is “a psychological bias where people to prioritize immediate rewards and satisfaction over future rewards”. In fact, this is only half right. Hyperbolic discounting also causes people to overvalue distant rewards in addition to overvaluing near-term rewards.
Temporal discounting is basically a way of thinking about how to answer questions like this one:
Would you rather have \$100 today, or \$120 one year from now?
This is relatively easy to think about in monetary terms, and you probably know that the answer to this question has to do with interest rates, and the idea that taking \$120 one year from now is equal to a 20% annual return, which is better than the 4-10% you might expect in the stock market, and also better than the 4.88% rate you can currently get for a 1-year treasury bond.
This model of calculating the interest rate is known as exponential discounting, and it’s basically represented by this equation:
$$ \text{value at time }t = \frac{a}{d^{t}} $$
This says that if something would be worth $a$ at time $t=0$, such as a \$100 bill now, then its value drops off exponentially the more you need to wait for it.
So it turns out that humans and other animals don’t appear to be using this equation to estimate the value of future rewards. Instead, they use something called hyperbolic discounting, which can be represented by this equation:
$$ \text{value at time }t=\frac{1}{1+dt} $$
This says that as a reward gets more distant, it’s value falls off according to an inverse.
How we Know
Scientists did experiments with undergraduates and \$100 bills. Realistically, grant funding is hard to come by, so most of them used \$10 bills, and researchers from lesser-known universities presumably had to get by with \$1 bills and some change.
They also did experiments with monkeys and juice. Monkeys love juice; I don’t know if any scientists have used Coca Cola for these experiments, but I bet they would replicate the same findings. Wow I was joking about that but here’s a paper where scientists gave monkeys cocaine. Science is fucking wild sometimes. They find that “[cocaine] choice behavior was largely consistent with hyperbolic discounting”.
I have not been able to find any experiments in which they test undergraduates with cocaine, so if you’re a grad student looking for a breakthrough paper, there’s an opportunity here.
I should note that the brain is complicated, and it’s an oversimplification to say that humans or monkeys always use hyperbolic discounting. This paper says that it varies by species, while this paper says that experimental evidence is strong, but that the laboratory setting is unrealistic.
Maths
Hyperbolic discounting is, in some sense, wrong. If you are a hedge fund and you use this equation to price the future returns of assets that you trade, you will lose money.
However, humans appear to think about the world this way, so it’s important to understand the implications of it. First, let’s plot these two equations against each other. You can follow along on Desmos.

🟦 = Exponential Discounting
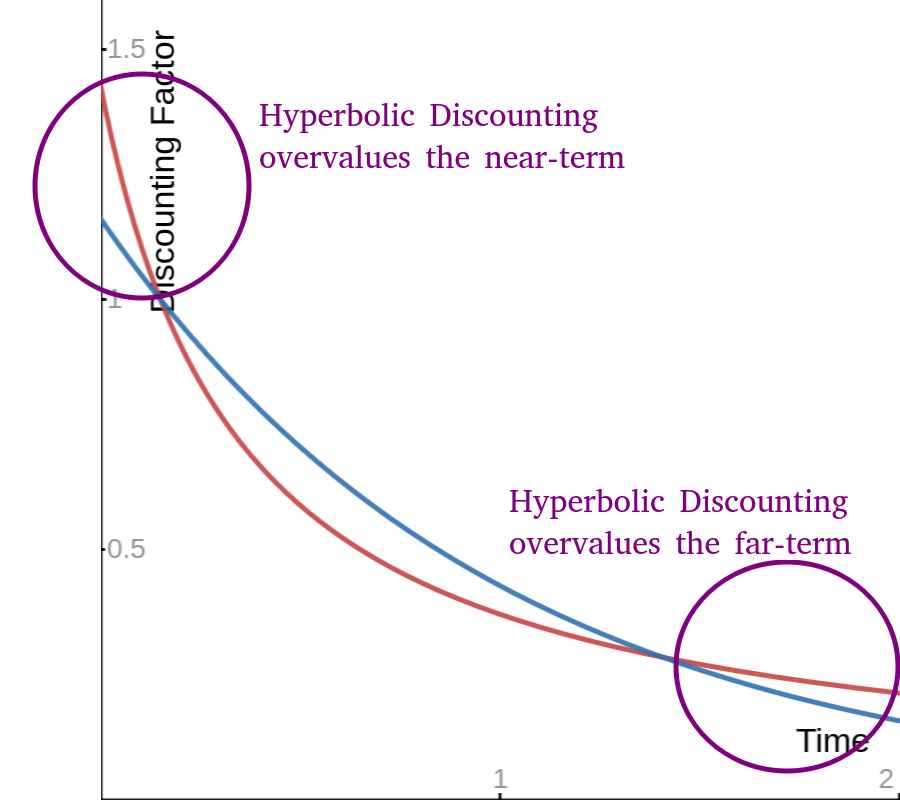
Wait, what’s going on here? Google told us that hyperbolic discounting overvalues short-term reward, but this graph is telling us the exact opposite! Hyperbolic discounting actually overrates long-term reward.
But it does seem like humans overrate short-term rewards, and that’s what all the self-help articles about hyperbolic discounting online have to say, although they don’t have graphs. Personally I like this one, which has good illustration:

If you squint at the graph, it looks like the hyperbolic curve overvalues things with a negative value of $t$. Let’s zoom out a bit.

🟦 = Exponential Discounting
There are several ways to square this circle, and they all boil down to basically this: Animals perform hyperbolic discounting for some reason, but they want to approximate the true discounting function, which is exponential, so evolution chose hyperparameters that minimize the discrepancy $\mathbb{E}[abs(hyperbolic – exponential)]$.
There are a lot of ways of tweaking the parameters on these two functions, but I like introducing a parameter which just shifts the graph over to the right, which essentially says that all actions we consider take some nonzero time and energy. You can see the equations on Desmos here.

🟦 = Exponential Discounting
Comparing the two equations side by side, we can see that hyperbolic discounting overvalues rewards that are distant, but it also strangely seems to overvalue rewards that are far away.
You can see that at $\text{time}=0$, hyperbolic discounting values things at a value greater than 1. That is to say, it overvalues them relative to their true value. I suspect this is one source of loss aversion, the phenomenon where humans tend to place too much value on the things that we already have, compare to the things that we could have.
Challenges as Well as Time
Before we get about the implications of this, let me talk about what is meant by time. In the world of finance, where you can put money in the bank and do nothing with it, time is your only resource. But in other areas of our lives, we have to actually put in effort to get rewards. Consider this question:
Would you rather sell your used furniture on Craigslist for \$100 today, or would you rather sell it for \$200 after you fix it up and repaint it in your garage?
This is similar to the “now or later” framing, except that there are two complications:
- You put your own labor into fixing up the furniture, so you’re effectively getting paid an hourly rate
- You might not do a good job painting it, so there’s no guarantee that it will actually be worth \$200 after you’re done with it
That second complication, challenges, actually shows up in the interest rate example above. If an experimenter asks if you would rather have \$100 now or \$120 in one week, you probably have the realistic expectation that the transaction is less likely to complete one week from now. After all, maybe you’ll forget about it, maybe the experiment will get shut down, maybe they’ll get your phone number wrong.
Here are some other situations where the x-axis is more about the uncertainty of complication than it is about time:
You sell furniture at the flee market. Someone offers you \$100 now, but you think it’s worth more. Should you hold out, hoping that someone will pay more for it later in the day?
Politician A promises incremental improvements that are achievable but unexciting. Politician B promises a utopian revolution, but it seems risky. Who should you vote for?
Consider each of these as a model where some reward $r$ will occur after the completion of $N$ challenges. Consider this hypethetical situation with Alice, an entrepreneur:
Alice wants to start a company selling shoes, which she thinks will be worth \$1,000,000. In order to succeed, she must do the following five tasks:
- Develop a comfortable shoe
- Find a factory to manufacture those shoes
- Create good branding for the shoes
- Convince influencers to market the shoes
- Fulfill orders
How should Alice balance the promise of reward against the 5 challenges that she faces? Exponential discounting suggests that each challenge will fail some percent of the time. Perhaps she is 50% likely to complete each task, or a $p_s=0.5^5=3\%$ chance of success. But hyperbolic discounting suggests that she’s more likely to estimate it like $1/(1+d*5)$. If $d=6$, she’ll get the same $p_s=3\%$ chance of success, but that doesn’t generalize. No matter what value of $d$ she fits to previous experiences, she’s going to systematically overrate her expected returns as the number of steps in her plan increases.
Why?
Why are humans like this? Why don’t we use exponential discounting, which is, in an abstract way, correct? Broadly speaking, there are two possible answers to this question:
- Actually, hyperbolic discounting is correct
- Math is hard, and brains can do some types of operations easier than others
Wikipedia outlines a nice argument for the “actually correct” answer which basically says that if there’s a constant background risk that something will go wrong at each unit of time (the hazard rate), but you don’t know what that level of risk is but you have some reasonable distribution over it, then hyperbolic discounting is mathematically correct. I don’t fully understand whether that distribution is a reasonable assumption. I think sometimes we have good data about the hazard rate and it’s hard to push that into our decision making.
A Neuroscience Just-So Story
But I also think there’s a neuroscience story. Computing an exponential function might be harder than computing the hyperbolic function, which only requires addition, multiplication, and division. After all, these equations look sterile on the page, but they represent a process of computation.
It’s surprising that calculating an exponential would be hard for a brain to calculate. Exponential growth and decay are all over the place in biological systems, such as in the half-life of drugs. The brain actually needs to carefully stabilize itself with negative feedback loops to prevent an exponential explosion of neural activity, which would result in a seizure. But all of those mechanisms take an amount of time that grows linearly with $t$, the amount of time in the future that you want to predict. The brain really needs to be able to evaluate the discounted value of actions in $O(1)$ time.
In Randall O’Reilly’s Axon model of reinforcement learning in the brain, the expected reward of an action is computed separately from the expected cost of that action. I think of it like Q-learning, where $Q^+(a)$ is the expected reward, and $Q^-(a)$ is the expected cost, which incorporates the delay. In this RL framing, the animal wants to pursue the action $a$ which maximizes $Q^+(a) – Q^-(a)$. However, there’s evidence from cellular processes that inhibitory neural connections are better represented as division rather than subtraction, giving us an equation like this:
$$ v_E(a, d)={\frac {Q^+(a)}{k_1+k_2Q^-(a, d)}} $$
Where $a$ is an action being considered, $d$ is the delay, and $k_1$ and $k_2$ are constants. This is exactly hyperbolic discounting.
Pascal’s Mugging
There are a lot of articles online telling us that hyperbolic discounting means that we overvalue things in the short term. Here’s a sample:
- Why do we value immediate rewards more than long-term rewards?
- Hyperbolic Discounting: Why You Make Terrible Life Choices
- “Hyperbolic discounting is … where people choose smaller, immediate rewards”
But when we look at plots of the equations above, we see that hyperbolic discounting also introduces a bias where we overvalue rewards that are far away! It’s actually the middle-term where we consistently undervalue things.
I believe this explains why people are consistently fans of unrealistic dreams that will hopefully occur in the far future. We find it more motivating to become a famous rock star than to become a pretty-good musician, even though it’s much less likely. Politically, people chase the promise of a revolution that will fix everything rather than moderate reforms.
In philosophy, Pascal’s mugging is a thought experiment demonstrating a problem in expected utility maximization. A rational agent should choose actions whose outcomes, when weighed by their probability, have higher utility. But some very unlikely outcomes may have very great utilities, and these utilities can grow faster than the probability diminishes. — Wikipedia
Pascal’s mugging can sometimes occur with exponential discounting, and it’s sometimes rational to pursue large-but-unlikely payoffs. For example, most pharmaceutical startups fail, but the ones that succeed tend to have very large profits, when they’re able to sell their drug under a patent monopoly.
But it’s much more likely to occur under hyperbolic discounting, which inappropriately uses an inverse instead of exponential decay.
The basic setup of Pascal’s mugging is this:
- There is a very large possible reward (heaven, utopia, benevolent AGI, a just king, fame and fortune, etc)
- There is a long list of reasons why this possible reward is unlikely to come about. Alternatively, the promised reward is very far away in time, with constant uncertainty for each unit time
It’s correct to discount the very large reward exponentially, and if you do so, you’ll see it diminish very quickly. But people don’t intuitively do that. Our neural hardware is set up so that we discount with a function that converges to zero much more slowly than an exponential. The only solution is to shut up and multiply.